
Zero-guidance Segmentation segments input images and generated text labels for all segments without any guidance or prompting.
Our method produces these results using only pretrained networks with no fine-tuning or annotations
VISTECว
Rayong, Thailand
Chulalongkorn Universityฬ
Bangkok, Thailand
ICCV 2023
Zero-guidance Segmentation segments input images and generated text labels for all segments without any guidance or prompting.
Our method produces these results using only pretrained networks with no fine-tuning or annotations
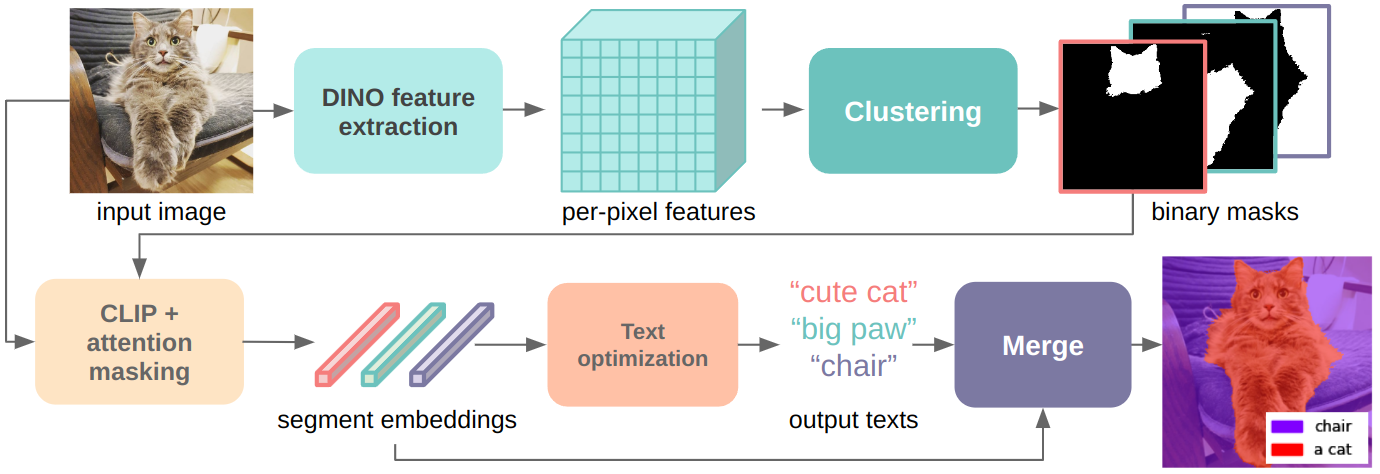
CLIP has enabled new and exciting joint vision-language applications, one of which is open-vocabulary segmentation, which can locate any segment given an arbitrary text query. In our research, we ask whether it is possible to discover semantic segments without any user guidance in the form of text queries or predefined classes, and label them using natural language automatically? We propose a novel problem zero-guidance segmentation and the first baseline that leverages two pre-trained generalist models, DINO and CLIP, to solve this problem without any fine-tuning or segmentation dataset. The general idea is to first segment an image into small over-segments, encode them into CLIP’s visual-language space, translate them into text labels, and merge semantically similar segments together. The key challenge, however, is how to encode a visual segment into a segment-specific embedding that balances global and local context information, both useful for recognition. Our main contribution is a novel attention-masking technique that balances the two contexts by analyzing the attention layers inside CLIP. We also introduce several metrics for the evaluation of this new task. With CLIP’s innate knowledge, our method can precisely locate the Mona Lisa painting among a museum crowd.
Our method first segments an input image by clustering learned per-pixel features extracted from DINO. The input image is then fed into CLIP’s image encoder. In this step, the produced segmentation masks are used to modify CLIP’s attention to provide embeddings that are more focused to each segment. The resulting embeddings are then used to optimize a trained language model to generate texts closest to these embeddings. Lastly, segments with similar embeddings and text outputs are merged together to form more coherent segmentation results.


BibTex

@inproceedings{rewatbowornwong2023zero,
title={Zero-guidance segmentation using zero segment labels},
author={Rewatbowornwong, Pitchaporn and Chatthee, Nattanat and Chuangsuwanich, Ekapol and Suwajanakorn, Supasorn},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={1162--1172},
year={2023}
}
